DirectX12 では描画コマンドを作成して画面表示までの様々な処理を自前で実装することになり、とても大変です。その中でも描画コマンドを構築した後、画面に表示されるまで、という箇所の理解は大変だと私は感じました。私自身とても不思議に思っていたこともあり、今回調べてみました。
ここに記載している内容は、私の調査結果に基づいています。そのため、参考元への問い合わせはしないようにお願いします。また、間違いも含まれている可能性がありますので、鵜呑みにもご注意願います。
DirectX 12 での描画コマンド構築、処理の流れ
DirectX12 で描画をする流れは以下の通りです。
- 描画コマンドを作成する (CPU側)
- 描画コマンドを発行する (CPU側)
- Present を発行してスワップチェインバッファを入れ替える (CPU側)
- 描画コマンドが GPU で実行され、バックバッファに書き込まれる (GPU側)
- 描画が完了したバッファが表示される
より正確には、描画完了したバックバッファが Present キューに入っており、次の Vsync タイミングで表示される、という挙動になっているようです(Vsyncありの話)。
処理開始、表示までのレイテンシ
CPU側でコマンドを作成し、それが表示されるまでのレイテンシを確認するのに、よい資料やツールがあります。
Intel が公開しているページを読むと、各条件下でオススメとなる設定がわかります。また諸条件でどのような動きになるのかを確認するためのサンプルプログラムを公開してくれています。これを用いると、描画コマンド作成から表示までのデータの流れを確認することができます。
別ツールの PresentMon は、各アプリケーションのレイテンシーを表示してくれるツールです。これを起動して、アプリケーションのレイテンシーが期待通りであるか確認するのもよいでしょう。 Releases ページからビルド済みファイルも取得できますし、アプリケーションへの組み込みも不要で動作するので、とても簡単です。
さて、私が以前に作成したプログラムでは、CPU/GPU 並列動作のために実行フレーム数:2,スワップチェインバッファ数:2、VSync あり、という条件で作成していました。これと同様の設定を Intel のサンプルプログラムでシミュレートすると以下の結果となりました。
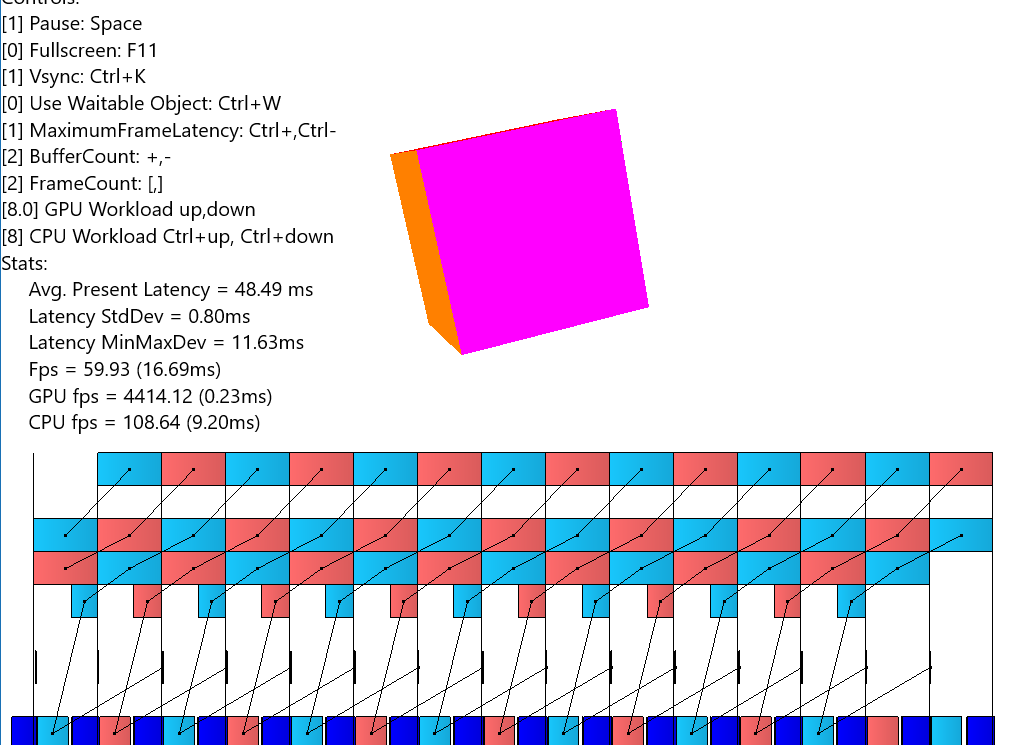
この場合では、処理開始から表示されるまでのレイテンシは 48ms (16ms x3) となっており、3フレーム分のレイテンシが発生しています。濃い青色ブロックは GPU 待ちとなっている部分で、それ以外の青と赤はスワップチェインバッファのそれぞれ対応する色分けとなっています。また、中段のブロックは Present Queue という表現をしています。一番上の帯は、ディスプレイに表示されているバッファを示しています。
PresentMon でもこのプログラムを動作中は 48ms 付近の値を示していました。
疑問点
ここで以下の点で疑問に思います。
- ダブルバッファリングしているなら、レイテンシは 33.3 ms 程度ではないのか?
- GPU の処理が、次フレーム単位ではなく、もう1つ先になっている点
- Present Queue って何者なのか
そこで、私のアプリケーションにも同じように各処理ブロックを計測するようにして、測定をしてみたものが次の図です。番号は処理しているフレーム番号です。上から順に、CPU実行、GPU実行、ディスプレイ表示バッファ、を示しています。先ほどと同じように3フレーム分のレイテンシーで、処理結果を画面に表示出来ていることが分かります。
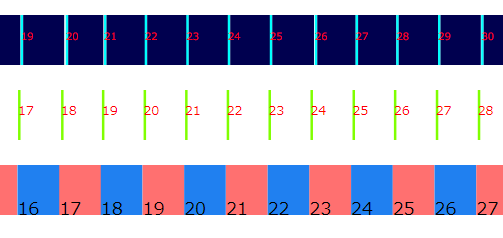
プログラム起動時の始めのほうでは、以下のようになっており、少し間隔が乱れていることもわかります。今回の計測時では 12 番目のフレームは表示欠落してしまったようです。何度か実行して計測し直してもほぼ似たような感じで乱れて、定常状態に入るようでした。
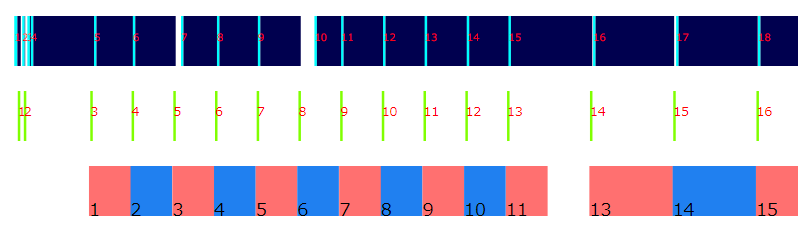
今回は Vsync 有効としているので、ディスプレイに表示されたタイミング = Vsync のタイミングであると考えると、均等に並んでいるのが自然ですが、ここでは12~15の間で通常とは異なる状況になっていそうです。
Microsoft のサンプルの場合
Microsoft が公開している Hello,Triangle のプログラムの場合、レイテンシは 32ms となっていました。同様の設定値で Intel のサンプルでシミュレートしたものが以下の図です。
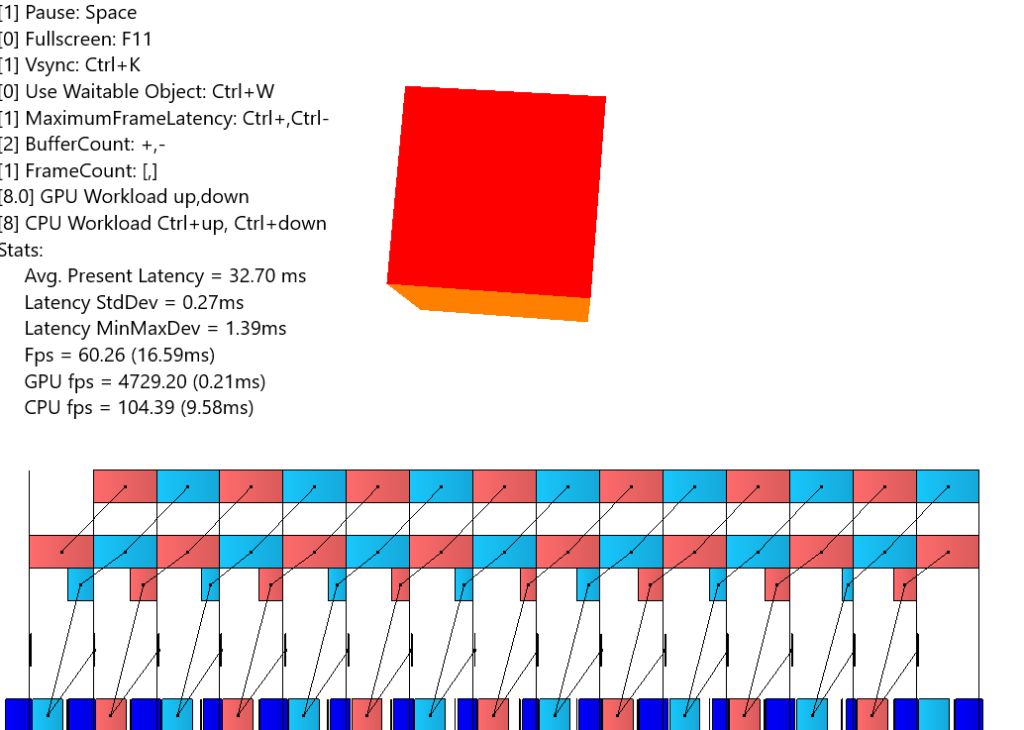
すぐに次のフレームでGPUコマンドが実行されて、描画画像が作られ表示される、という図になっています。そして、Present Queue の深さも変わっています。
フレームが実際に実行され、表示までの間に Present Queue に入る、という部分が今回の釈然としない原因になっているように感じます。
Present Queue とスワップチェインバッファ
ここからは、これまでの情報と挙動からの推測です。
スワップチェインで確保したバッファは、触れない(書き込めない)タイミングがある、ということです。Present API で Present Queue に入ってしまったバッファはキューから抜けてくるまで描画先に出来ないようです。実際に連続してコマンド構築、Present の発行を高速に実行すると、以下に示すエラーが報告されました。 (なお、Device Removed 状態になります)
A command list, which writes to a swapchain back buffer, may only be executed when that back buffer is the back buffer that will be presented during the next call to Present*. Such a back buffer is also referred to as the “current back buffer”.
Present Queue に入り、次の Vsync で表示を待っているバッファへの書き込みは、(新規には)出来ないということでしょうか。
そして、この部分をみると CPU でコマンドを作って Present したタイミングで 赤色のバッファがキューに追加されています。しかし、そのときにはキューの一番深いところには同じく赤色のバッファが待機しています。このバッファは次のタイミングで画面に表示され、そのタイミングで再度利用可能状態に戻るのかなと考えられます。ここで私が誤解していたのではないかと考える点が、ディスプレイ表示中=スワップチェインバッファに触れない期間、という認識です。ディスプレイへの表示を開始したら、そのスワップチェインバッファはカレントのバックバッファとして戻ってきている、と考えると、これらの辻褄が合うように感じます。
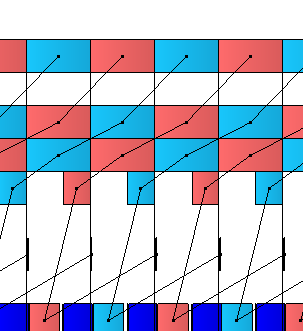
そのため、表示を開始したあとはバックバッファとして利用可能な状態になるので、GPU コマンドを実行可能な状態として揃うので、このタイミングのズレが生じてくるのだろうと考えられます。
まとめ
ようやく予想を立てられるところにはなりましたが、スワップチェインバッファと実表示とコマンドの実行との関連は、分からないところが多いと感じます。昔は表と裏面を入れ替えるだけのダブルバッファリング、という話も聞きますし、現在は複雑化していて難しいですね。
とりあえず、CPU/GPU を並列動作させたり、トリプルバッファリングさせたりすると、レイテンシが延びるのは真実であるといえそうです。
※ 今回の内容で詳しい方がいらっしゃいましたら、コメントで情報をいただけるととても助かります。
コメント