
手元にあったラズベリーパイ4 4GBモデル品を束ねて、Qwen 3.5 9B のモデルを動かしてみた記録です。動作するには動作しましたが、結論として実用は難しいでしょう。
ハードウェア構成
- Raspberry Pi 4 (4GB) を 3台
- Raspberry Pi OS Lite (64bit)
ストレージには microSD を使用しています。全体をコントロールするサーバーの機材には 128GB のカードを使っており、それ以外は 32GB程度の microSD を使用しています。
ラズベリーパイ同士は Hub 経由 1GbpsのLAN接続をしています。
ソフトウェア
LLMを動かすのに、 llama.cpp を使用しています。この実験的機能をつかって、分散処理をしています。なお、vulkanバックエンドもありましたが、Raspberry Pi の V3DVドライバが入った状態でも活用できなかったので、 CPU による推論実施になっています。
llama.cppではGGUF形式のものが使えるようです。そこで、今回は Qwen3.5-9B-Q4_K_M.gguf のモデルを使っていきます。これは今回使用している単独のラズベリーパイ4のメモリでは動作不可能なものとして選択しています。
llamaの準備
リポジトリをgitでcloneして、cmakeでビルドしていきます。ここでは以下のように実行体などを作ってインストールを進めました。ビルド時のポイントとして、-j を指定したときには手加減したジョブ数の設定が必要でした。
$ cmake -B build-cpu -DGGML_RPC=ON -DLLAMA_BUILD_TESTS=OFF -DLLAMA_BUILD_EXAMPLES=OFF
$ cmake --build build-cpu --config Release -j3
$ sudo cmake --install build-cpu --config Releaseまたインストール後、実行するために、1度以下のコマンド実行しておきます。これを忘れると、共有ライブラリのロード・解決で失敗します。
$ sudo ldconfigプログラムらを各ラズベリーパイに配置しておきます。もしくはそれぞれの環境で上記の手順を繰り返してください。
ワーカーの起動
計算資源を提供するワーカー側を先に起動します。起動コマンドは以下のようにします。実験のため、0.0.0.0:50052 で待ち受けを設定しています。
$ rpc-server --host 0.0.0.0 -p 50052 --threads 4サーバーの起動
サーバーを起動します。サーバーの起動時には、モデルファイルが必要になるので適当に準備しておきます。ここでは、models/Qwen3.5-9B-Q4_K_M.gguf にファイルがあるとしています。また、WebUIでチャット機能が使えるように、その設定(–host, –port)も含めています。
$ llama-server -m models/Qwen3.5-9B-Q4_K_M.gguf --ctx-size 65535 -fa on --host 0.0.0.0 --port 8080
--rpc (ワーカーのアドレス1):50052,(ワーカーのアドレス2):50052“–rpc” 引数にて、ワーカーの情報を設定します。既に準備をした2つのワーカーのアドレスを記入します。
“–ctx-size” 引数でコンテキストサイズの指定をしています。今回は64KBほどにしています。本来は 128K, 256KBなどを指定したかったのですが、その指定ではメモリが不足するのか、3台のラズベリーパイではサーバー起動に失敗しました。
起動して、準備が完了するまでにはしばらくかかります。サーバー側から各ワーカーへ必要なデータが転送されるので、その待ち時間となるようです。
動作の確認
サーバーが起動して準備も完了となったら、WebUIに接続してみます。ここからは Chat などを使うことが出来るので、早速推論が動作するかをみてみます。
簡単な日本語の文章を生成してもらおうと思って、次のように入力しました。
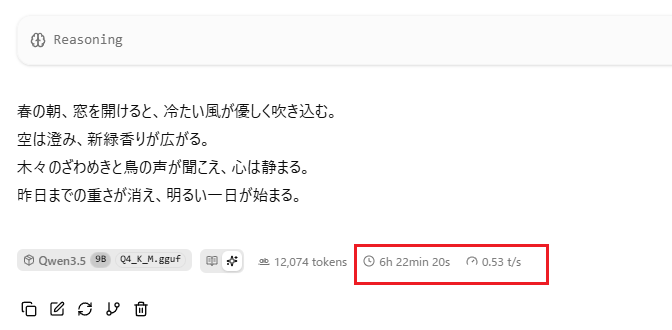
上記のスクリーンショットを見てもらうと分かるように、動作はしているようです。しかし、とても遅い点に注意が必要です。どのくらい遅いかというと、先の質問の答えに6時間を越えています。以下のスクリーンショットに回答と所要時間を載せています。

所感など
ラズベリーパイ4を束ねて、9Bモデルが動作しました。実用できるかというと難しいでしょうが、動くところにロマンを感じます。束ねた結果10GB程度のメモリが使えそうというところでした。ちなみに、このくらいのサイズなら、12-16GBのVRAMを備えたGPUでスムーズに動いてしまうので、なおさら今回の試みはお遊びだった感じですが。
CUDAやVulkanなど、ちゃんとGPUを活用した分散環境だと、また違った結果になると思うので、引き続きトライしてみたいと思います。
コメント